反爬研究
在和A师傅的交流过程中,明确了反爬技术是很重要的,对于头条产品来说主要考虑是视频版权。对于电商的黑产,主要是羊毛党比较多。因此在这里快速学习一下反爬技术。
爬虫技术
常规编写思路
-
分析页面请求格式
-
创建合适的http请求,验证请求的准确性
-
编写脚本,批量发送http请求,获取数据
代理池
概念
为了保证代理的有效性,我们往往可能需要维护一个代理池。这个代理池里面存着非常多的代理,同时代理池还会定时爬取代理来补充到代理池中,同时还会不断检测其中代理的有效性。当然还有一个很重要的功能就是提供一个接口,这个接口可以随机返回代理池中的一个有效代理 公众号文章:Link
隧道代理
隧道代理无须切换 IP,将 IP 切换的事情交给隧道来做,程序只需要对接一个隧道代理的固定地址即可, e.g. xxproxy:7777 平台在云端维护一个全局 IP 池 供短效代理 IP 产品使用,池中的 IP 会不间断更新,以保证 IP 池中有足够多的 IP 供用户使用 隧道代理 基于 HTTP 协议,支持 HTTP/HTTPS 协议的数据接入。
如何实现
使用Squid代理服务器实现一个隧道代理的代理池。
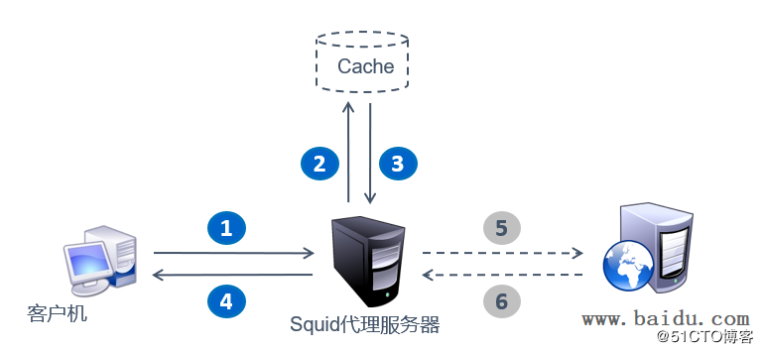 图:Squid工作机制
客户机请求web服务,通过Squid代理服务器,代理服务器检查web页面是否在缓存中。如有,直接返回;如果没有,则让Squid代理服务器去发起请求,获得缓存页面,再返回给客户机。
使用Squid的cache_peer功能,可以实现二次代理转发。因此,配置在Squid代理服务器的二级代理可以是批量的,不断变化的,而Squid服务器本身只留出固定的端口与客户机进行交互,从而实现一个简易的代理池的功能。
参考文章:Link
图:Squid工作机制
客户机请求web服务,通过Squid代理服务器,代理服务器检查web页面是否在缓存中。如有,直接返回;如果没有,则让Squid代理服务器去发起请求,获得缓存页面,再返回给客户机。
使用Squid的cache_peer功能,可以实现二次代理转发。因此,配置在Squid代理服务器的二级代理可以是批量的,不断变化的,而Squid服务器本身只留出固定的端口与客户机进行交互,从而实现一个简易的代理池的功能。
参考文章:Link
传统反爬技术
限制User-Agent
建立User-Agent白名单,对其进行检查。
对抗
设置user-agent,可以从一系列的User-Agent列表里里随机挑出一个符合标准的使用
通过IP限制
监控单个IP的访问情况,结合第三方情报平台,建立IP黑名单。
对抗
使用IP代理池,参见“爬虫技术”模块。
验证浏览器客户端
使用JS脚本可以要求浏览器(客户端)进行计算等进行验证,用以识别真实浏览器和爬虫脚本。
对抗
使用模拟浏览器的Python包,例如PhantomJS,本身适用于自动化测试,但可以在对效率要求不是非常高的情况下使用于反反爬虫。
_PhantomJS_是一个无界面的,可脚本编程的WebKit浏览器引擎
完善robots.txt来限制
在robots.txt中更新活跃程度高的恶意爬虫,也就是黑名单。
对抗
使用这些恶性爬虫的时候,更改请求头参数,伪装自身。
访问统计及分析(传统)
- 后台对访问进行统计,如果单个IP访问超过阈值,予以封锁
-
效果还行
-
容易误伤
-
有较多的对抗手段(IP代理池)
-
后台对访问进行统计,如果单个session访问超过阈值,予以封锁
-
效果差
-
后台对访问进行统计,如果单个userAgent访问超过阈值,予以封锁
-
效果好
-
误伤严重
-
对抗:爬虫脚本可以随机浏览器类型
-
以上三种的组合
-
能力变大,误伤率下降,但只能防部分低级爬虫
-
参考:Link
反爬新思路
来自GEETEST
工作量证明
反爬虫实际上是一场成本拉锯战。 如果我们能要求某个客户端的证明其工作量,要求完成某个特定计算,比如生成设备指纹,要达到某个工作量才能下发指纹。 可行的方法,比如是增加前端JS加密混淆,增加破解成本,也增加了中间人破解成本
轨迹模型
使用通过智能技术进行人机识别。 TODO
前端加密
增加前端JS加密混淆,增加破解成本,也增加了中间人破解成本。这个和工作量证明其实是泛化的关系。
网络层特征
SSL + TCP, 通过更底层的协议分析,提高数据采集的隐蔽性,从信息差上获取赢面。
一个反爬业务模型
- 反爬需要分析出异常的流量,并对异常流量进行分类处理
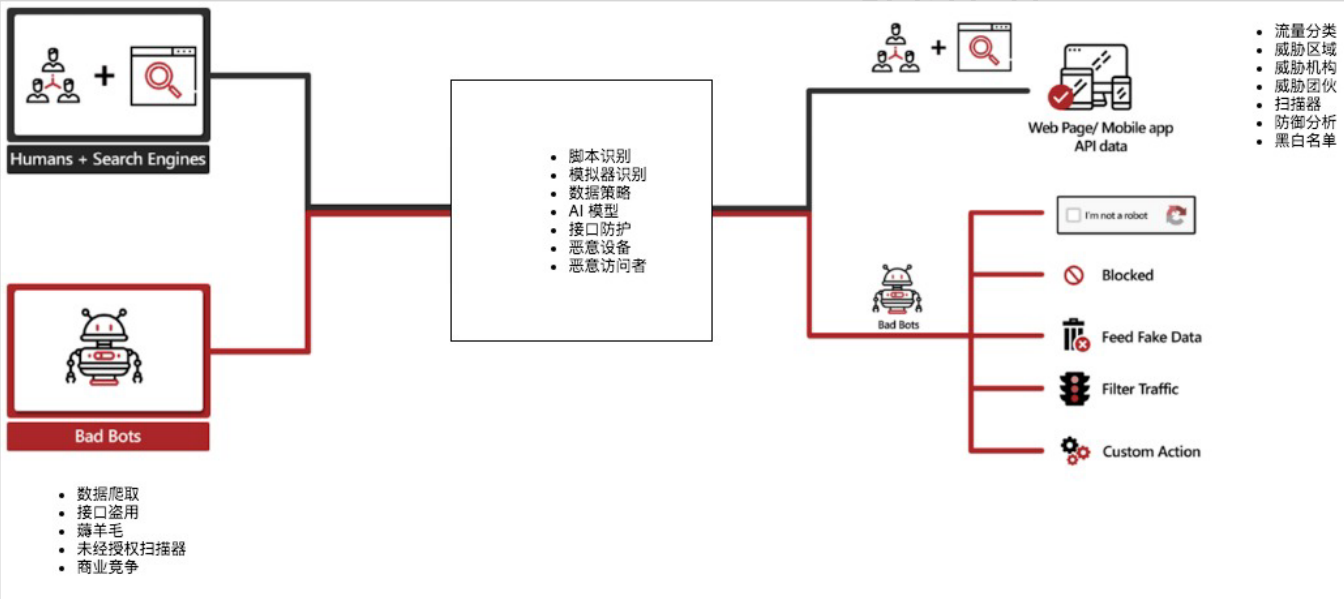
- 恶意爬虫的行为
-
数据爬取
-
接口盗用
-
薅羊毛
-
未经授权扫描器
-
商业竞争
-
识别的方法
-
脚本识别
-
模拟器识别
-
数据策略
-
AI模型
-
接口防护
-
恶意设备
-
恶意访问者
-
防护的手段
-
验证码
-
Block(封禁)
-
Feed Fake Data(假数据)
-
Filter Traffic(监控模式)
-
Custom Action(自定义的其它手段)
流量过滤分析
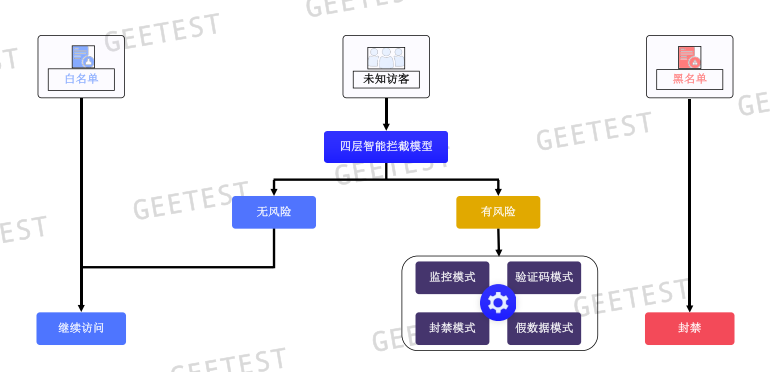
四层防护逻辑
- 设备环境监测
-
数据串改
-
设备指纹
-
混淆加密
-
特性测试
-
特性采集
-
工作量证明
-
建立海量风险库
-
IP打分体系
-
黑产IP
-
爬虫IP
-
团伙IP
-
云服务器IP
-
设备指纹风险
-
网络风险探测
-
TCP特征
-
HTTP特征
-
大数据统计
-
人工智能模型
-
鼠标轨迹CNN模型
-
流量分析(行为分析)
头条反爬研究
头条反爬策略
-
封IP —— 使用代理池
-
网页文章链接(关键内容),通过另外的url请求获取,同时进行加密处理
-
对网页JS函数进行加密处理
-
视频通过videoid获取网页播放链接,经过三次加密处理才能获取最终url
-
翻页请求失败率高,降低爬虫获取信息的速度
- 使用自定制的JS加密算法 —— 添加断点进行调试(分析其算法机制)
对抗
-
首先找信息列表和下拉方式的URL规律,分析获取单页面信息的规律
-
能读懂前端代码
-
多从网络上找新的思路
-
添加断点进行调试,分析其算法机制(静态分析、动态调试、步步跟进)
头条反爬总结
参考
- 《今日头条反反爬思路总结》,分析得很详细,很值得一看:Link
案例
巧达科技被查
公司客户信息被抓取,并且某个接口访问量巨大,后调查为一个数据公司的某个程序员将爬虫的线程数调大,影响了正常服务
hui产公司
idataapi
https://www.idataapi.cn/product/detail/94
爬山虎采集器
可进行头条数据采集的一个爬虫软件 http://www.51pashanhu.com/