数据驱动安全入门概览
此内容是Nepnep成员 peony师傅的一次每周分享[1]简单笔记,感谢师傅~
“数据驱动安全的本质是一种高层次、跨学科的自动化手段,其内涵包括了数据分析、人工智能、大数据、云计算等等。数据分析技术作为一种重要的自动化手段,必然会消灭掉一部分简单、重复工作内容,进一步提高行业从业人员的进入门槛。在未来可以预期的很长一段时间内,数据分析都将是安全工程师和研究人员的有力工作助手。”
安全数据分析能力图
从数据中提取知识,辅助解决安全问题
- Hacking Skills
- Math & Statistics knowledge
- Substantive Expertise(先验专家经验)
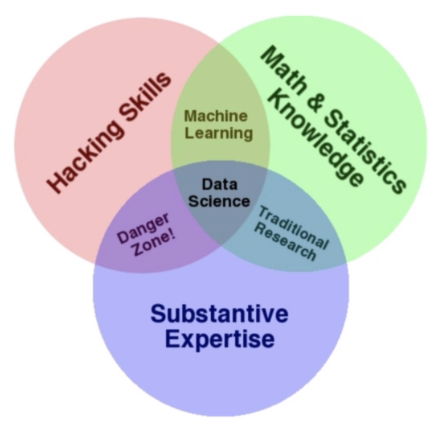
图:安全数据分析能力图
安全数据分析落地情况
给予历史经验样本下的拟合学习
基于知识的对抗
文本内容监测
- WAF
- WebShell检测
- 二进制病毒检测
- 网页敏感内容检测
- 明码流量检测
简单统计和假设检验
- 暴力破解攻击检测
- 异地登录检测
- 真实入侵证据发现
时序建模和时序异常监测算法
- DDoS
- CC
- 定点API接口爆破检测
相似性匹配算法
- 缺乏可解释性,目前更多用于辅助专家决策
安全数据学习概览
方法论
问题——数据——特征——模型
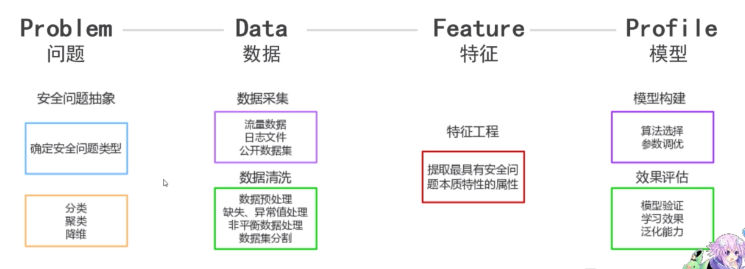
图:机器学习方法论
问题
安全问题抽象
数据
数据采集
特征
特征工程
模型
模型构建
效果评估
ML Workflow
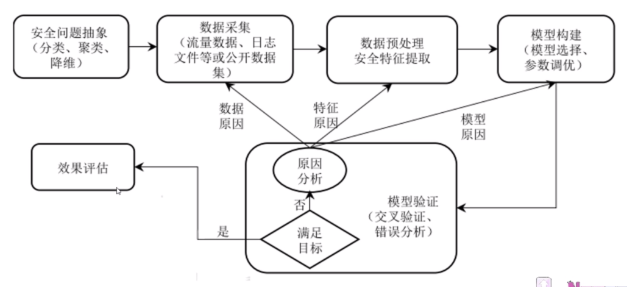
图:ML Workflow
目标
更快、更全、更准

图:安全数据分析的目标
安全问题抽象
分类、聚类、降维

扩展
减少误报率的方法:基于业务来减少误报率。对不同业务场景下,对单一的业务逐个进行进行验证,不断将误报的样本送回进行训练,从而降低误报率
数据挖掘
安全数据来源、安全数据类型
最优数据量:多到特征明显,少到几乎无噪音干扰

图:数据挖掘
数据清洗

图:数据清洗
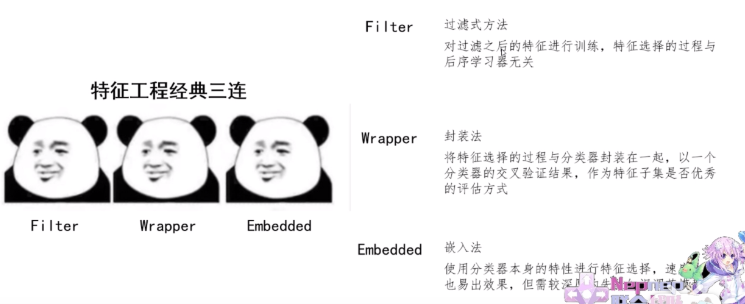
特征工程
过滤、封装、嵌入
模型
数据脚本小子
策略选择
白名单策略:找到正常行为——建立pattern(模式)——滤出异常
- 业务改变时,需要重新进行聚类
- 无监督聚类的效果还没有达到有监督的好,容易尝试误报
黑名单策略:原始日志或异常——分类器——识别威胁

图:常用的两种策略
案例
两个角度
对抗:对深度学习的逃逸攻击
防护:HTTP恶意外连流量的机器学习检测
案例一
对深度学习的逃逸攻击

参考:https://blogs.360.cn/post/evasion-attacks-on-ai-system.html
案例二
HTTP恶意外连流量的机器学习检测
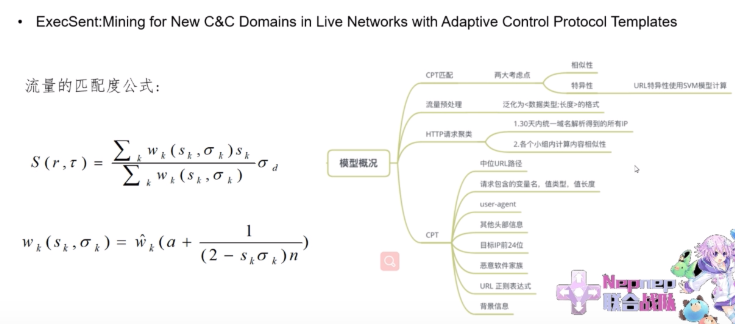
图:论文概要和笔记

图:控制协议模板的生成
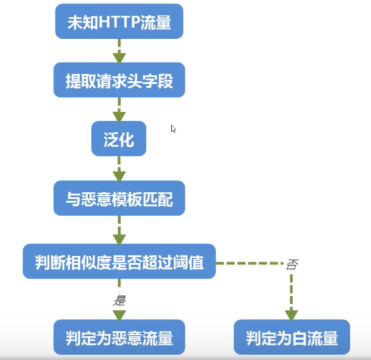
图:主要的流程示意图
泛化其实就是用来进行数据降维的一种方式

图:上图的泛化部分示意
Reference
[1] 【每周分享】数据驱动安全入门概览,Nepnep战队,https://www.bilibili.com/video/BV1ye411W7xn