数据分析相关
对于黑灰产的分析,会用到数据分析相关的知识。从数据获取——数据预处理——数据整合——数据分析——数据可视化/形成报告。在风控这块,最后能还原攻击特征,甚至写一些自动化监测、分析的脚本,最后能将这些特征加入风控规则内。
资料整合
整合一些和企业安全相关的数据分析资料
安全数据分析
总体的流程

- 数据采集——格式化——管道输出——统计分析——结果处理——可视化
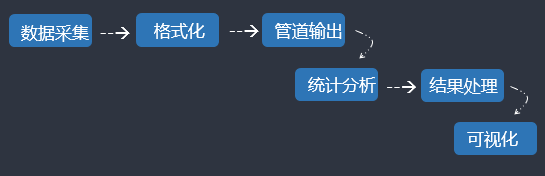
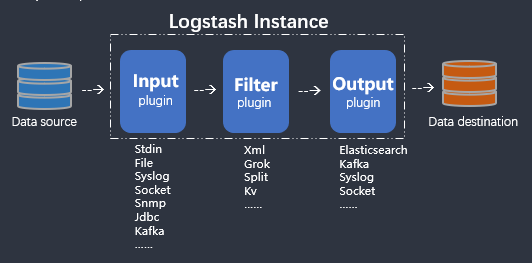
- 数据采集(以日志分析为例)
建模思路
- 两种基础的建模思路

大数据预警溯源
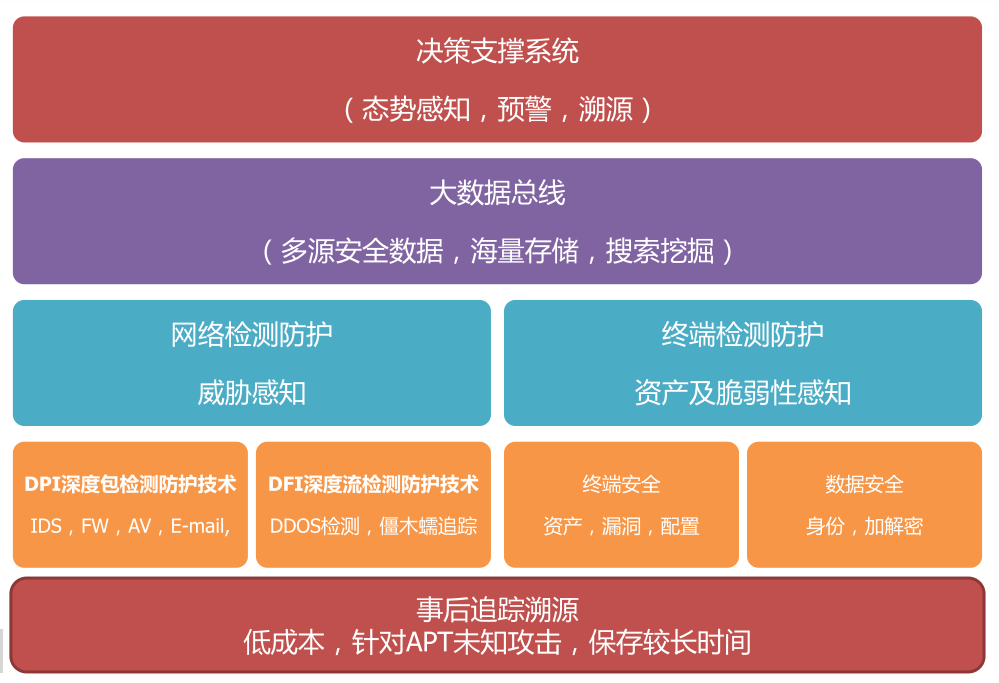
图:发达国家预警溯源平台
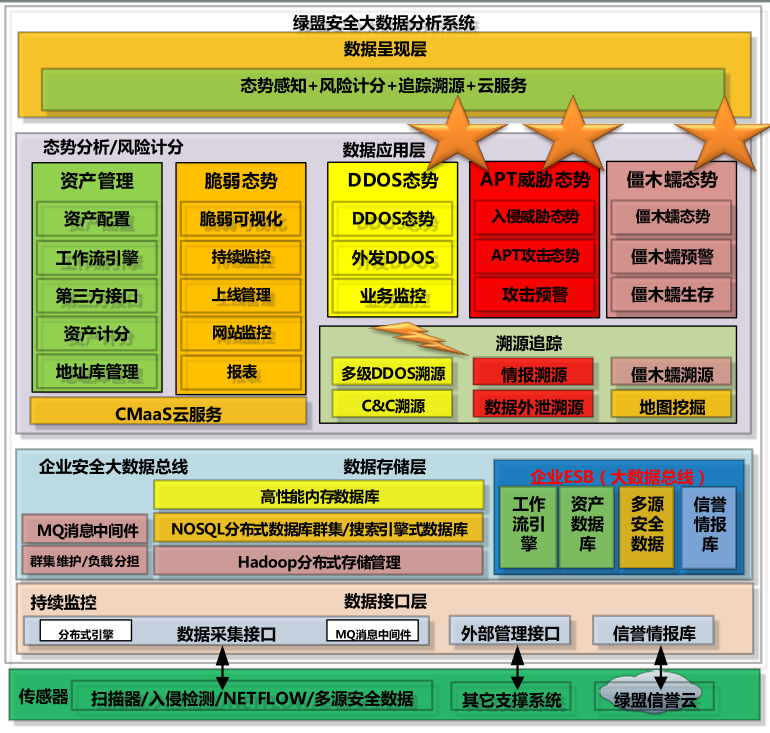
图:绿盟安全大数据分析系统
万能溯源
- 对任意IP进行分析
- 分析统计流量
- 分析访问的来源
- 渐进地分析流量的组成
- 地图挖掘(根据流量的不同地区,选择不同的挖掘力度)
数据挖掘
- 渐进式挖掘
- 地图挖掘
- TODO
数据取样
- 关键词取样
- 根据特定的关键词及关键词组合,从全集数据中提取与特定分析对象或特定分析场景有关的数据子集
- 主要用于数据统计或趋势分析
- 相似度采样
- 根据文本或样本数据的相似度,从全集数据中提取具有较高相似度的数据子集
- 主要用于数据分类统计或案例分析
- 随机采样
- 对未知类型或内容数据进行简单随机采样,抽样比例根据具体的分析场景决定
- 主要用于情报线索发现或关键词校验
- 分层采样
- 对已知工具/事件数据按既定的标签规则分为若干子集,对每个子集中的数据随机抽取部分数据进行分析,抽样比例根据具体分析场景决定
- 主要用于案例分析或关键词校验
- 人工经验判断
- 受限于数据获取的渠道、数据本身的变化、抽样概率的限制及样本噪点的影响,需要采取人工经验判断的方式进行修正
聚类分析
定义
聚类分析是根据在数据中发现的描述对象及其关系的信息,将数据对象分组。
目的是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内相似性越大,组间差距越大,说明聚类效果越好。
例如,在实际过程中,分析灰黑产的流程和工具,对被攻击的接口请求进行特征汇总。使用聚类分析的方法,将正常请求和恶意请求进行分组汇总。
聚类效果的好坏依赖于两个因素:
1.衡量距离的方法(distance measurement)
2.聚类算法(algorithm)
一篇文章透彻解读聚类分析(附数据和R代码): Link
衡量距离的方法
- 数值变量
- Minkowski 距离:X和Y是两个向量,
,
,那么
,q 是正整数
- Euclidean 距离:是Minkowski,q=2时的特例
- Manhattan 距离: 是Minkowski, q=1时的特例
- Mahalanobis 距离:权重向量
,那么
-
二元变量
-
分类变量
-
有序变量
聚类算法
-
K-均值聚类(k-means)
-
1.选择 K 个初始质心,初始质心随机选择即可,每一个质心为一个类 > 2.把每个观测指派到离它最近的质心,与质心形成新的类 > 3.重新计算每个类的质心,所谓质心就是一个类中的所有观测的平均向量(这里称为向量,是因为每一个观测都包含很多变量,所以我们把一个观测视为一个多维向量,维数由变量数决定)。 > 4.重复2. 和 3. > 5.直到质心不在发生变化时或者到达最大迭代次数时
-
实例
- 随机选择3个初始质心,每个质心为一类
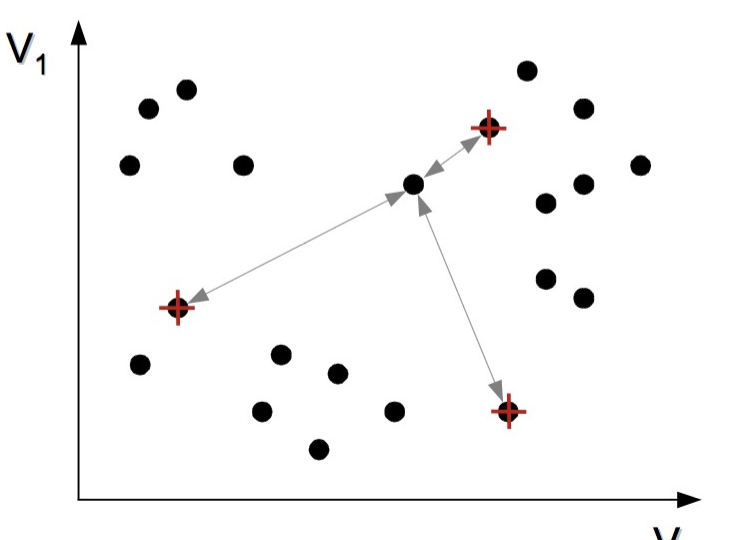
-
计算每一个不是质心的点到这三个质心的距离
-
将这些点归类于距离最近的那个质心的一类
-
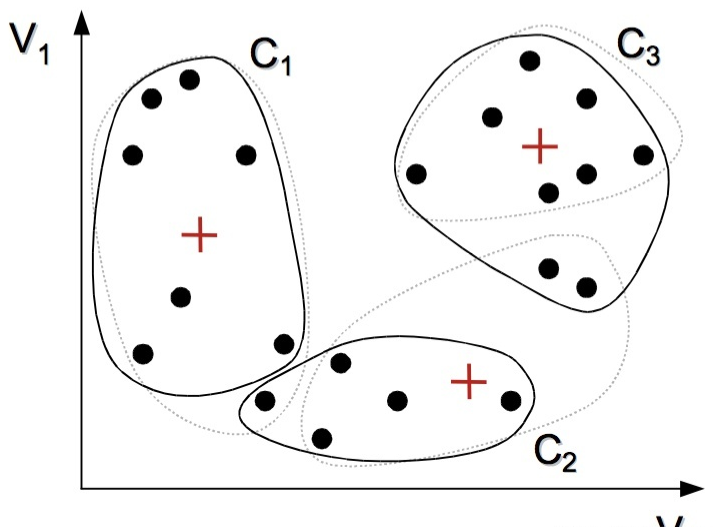
重新计算这三个分类的质心
-
不断重复上述两步,更新三个类
- 当稳定之后,迭代停止,这时候的三个类就是最后的结果
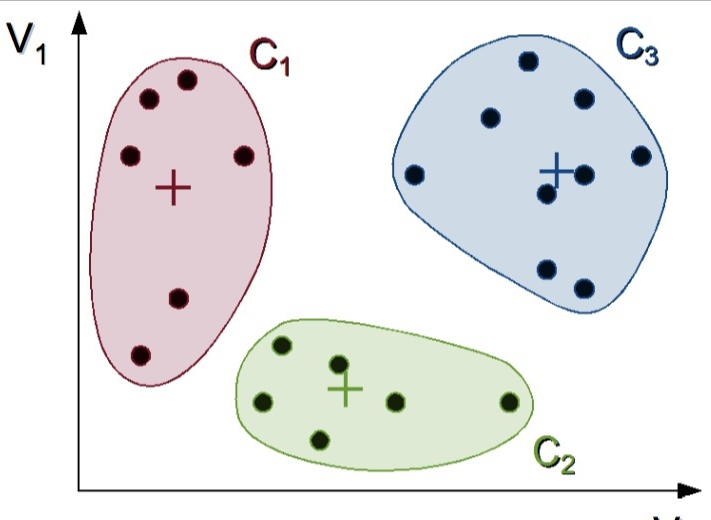
-
层次聚类(Hierarchical)
-
根据密度的聚类
-
根据网格的聚类
交叉分析
-
研究黑灰产产业链特征,对比核心业务的产业链特征,进行交叉分析(总结产业链中角色交叉衍生产业链的上游,并对上游人员监控)
-
批量行为都是有迹可循的,可以在在设备信息、注册信息重合度、 恶意用户的行为数据等方面,进行多维度的判断
建模分析
结合自身后台数据的黑白名单,行为建模、分析等 TODO
可视化查询
- 分析攻击源流量,通过力导向用(来呈现复杂关系网络的图表图),找到共同的通讯IP