威胁情报自动化生产
本文从看到果胜师傅的“浅谈基于开源工具的威胁情报自动化生产”[1]一文开始思考和整理。
在经过自己一段时间学习后发现,威胁情报的自动化生产过程,在场景上很受部署环境、应用场景的限制,在本篇中所整理的威胁情报生产是在一个理想化的宽松环境下进行:可联网,不考虑数据敏感度,不考虑其他部署环境的限制,不考虑数据源限制。
关于威胁情报本地化生产的部分,将在《威胁情报私有化生产》一文中给出。(挖坑现场,咕咕咕)
背景
“对于红队和渗透测试人员来说,获取更多的漏洞情报,将自己的基础设施和工具链条隐藏在已知威胁情报之外也是提高行动成功率的重要措施”[1]
"如果不能在本地结合自身业务对互联网威胁情报平台的海量数据进行提取,则威胁情报的对安全工作的指导意义会大幅下降。"[1]
攻防对抗的本质是成本的对抗,从这个角度来看,威胁情报的建设和应用,不外乎:威胁情报 + 本地化(结合业务) + 自动化。
方法论
威胁情报的本地化生产(其实就是定制化的意思),主要包含:
- 获取与自身相关的IOC
- e.g. hash, ip, url...
- 来源于本地设备,OSINT,SRC等
- 逐步扩张IOC
- 第一步是进行评估现有,基于痛苦金字塔模型
- Pyramid of Pain 可以用来评估IOC价值,价值从到高

- 第二步是使用人工或者自动分析系统(沙箱)分析原始IOC,从而产出更高价值的关联IoC指标
- 第一步是进行评估现有,基于痛苦金字塔模型
- 集成威胁情报
- 集成就是讲数据标准化后进行存储和共享
- 例如,MISO, STIX等多个威胁情报共享标准
以上内容来自果胜师傅的总结[1]
生产架构
下图是来自2020 奇智威胁情报峰会的分享[2],其中主要组成为4个维度:
- 外网
- 内网
- 文件
- 流量
其中的数据流动关系主要为:流量==>文件==>内网==>外网。其中流量层的数据维度最为丰富,一般作为数据源,通过对异常网络行为的分析,提取相关文件进行样本分析。内网威胁情报分系统中的“内网”是相对企业/组织内外部而言,不一定是表示网络层面上的内外网。在内网部分,经过分析的样本信息作为线索,与内部的情报数据进行关联归因。在外网部分,通过外部多个情报源数据的孵化,结合数据科学的技术,可以对多源异构的大批量数据进行匹配、关联、聚合等,从而实现威胁情报视角下的组织关联分析(组织归因)等需求。
P.S. 为什么需要划分内外网呢?猜想,主要是对于企业/组织来说,外部的威胁风险肯定是与自身不同的,外部的情报源数据更加广泛,导致关联时孵化的数据不一定适用于自身。
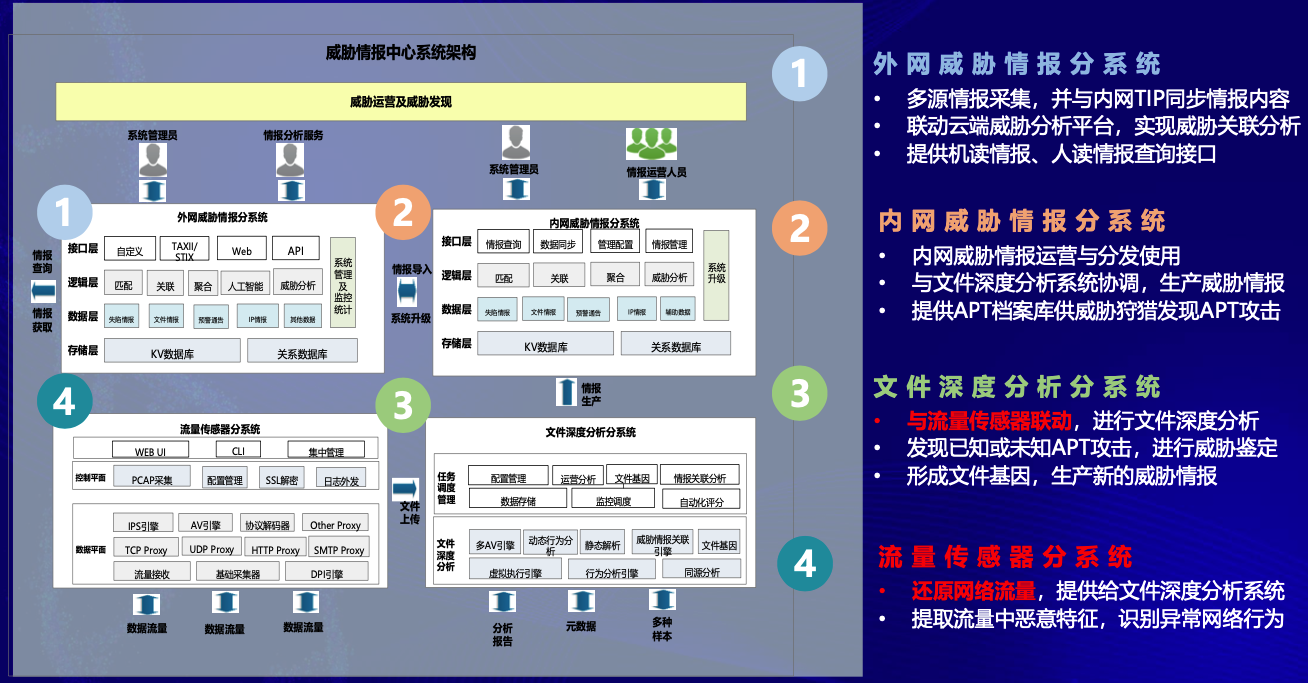
图:奇安信的威胁情报生产架构
系统搭建
针对小型或起步的SoC来说,开源工具搭建+少量开发是非常好的方案。
开源工具选择
TreatIngestor
-
项目地址:https://github.com/InQuest/ThreatIngestor
-
“ThreatIngestor是inquest实验室推出的一个威胁情报采集框架,该框架可以从社交媒体,消息队列,博客,自定义插件等渠道采集可用于威胁情报的IOC信息,并以编排剧本的方式灵活的配置采集和处理信息的具体步骤“[1]
TheHive
- 官网:https://thehive-project.org/
-
项目地址:https://github.com/TheHive-Project/TheHive
-
介绍:TheHive是一个可扩展的4合1开源和免费安全事件响应平台,旨在使SOC,CSIRT,CERT和任何需要迅速调查并采取行动的信息安全从业人员,更加轻松。
Cortex
- 项目地址:https://github.com/TheHive-Project/Cortex/
- TheHive的后台分析引擎,用于对IoC进行可视化、批量分析
- “cortex比主项目thehive具有更好的API SDK和文档支持,更加方便与第三方代码集成。”
Beats
Beats :轻量级,单一用途的数据发布者,可以将数百或数千台计算机中的数据发送到Logstash或Elasticsearch。
搭建过程
使用ElasticSearch
$ brew install elasticsearch
$ brew install kibana
笔者使用macOS可以直接用homebrewan安装,es运行在后台9200端口
Fig. ElasticSearch后台(9200端口)界面
使用Kibana
Kibana提供es的一个可视化面板进行管理和应用,也是在测试阶段我们所采用的开源可视化面板。

Fig. Kibana面板界面(5601端口)
使用Logstash
Logstash是一个数据加工系统,可以使用这个该将数据导入到ES内。
搭建Cortex
可以使用Docker便捷安装,但使用官方给出的docker-compose.yml时,会出现cortex不兼容elasticsearch5.6.X版本以上的情况。而ES 5.6.X会意外退出,暂时还没有找到原因。因此这里采用TheHive官方提供的一个培训用虚拟机,可以更便利地使用。当然,在生产环境中还是要本地安装和配置。
训练用虚拟机_下载地址:https://github.com/TheHive-Project/TheHiveDocs/blob/master/training-material.md
使用虚拟机软件import ova文件即可,Virtualbox用户需要把网络选项设置为桥接。
- Training VM system account (ssh) :
thehive/thehive1234- TheHive URL : http://IP_OF_VM:9000
- TheHive Admin account:
admin/thehive1234- Cortex URL : http://IP_OF_VM:9001
- Cortex superAdmin account :
admin/thehive1234- Cortex "training" Org admin account :
thehive/thehive1234(its key API is used to enable Cortex service in TheHive)
使用TheHive
The Hive是一个开源的应急响应平台,其依赖于ElasticSearch、Cortex,以下是一个Docker部署的方案,来自DockerHub,会同时部署ES和Cortex。
version: "2"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.0
environment:
- http.host=0.0.0.0
- transport.host=0.0.0.0
- xpack.security.enabled=false
- cluster.name=hive
- script.inline=true
- thread_pool.index.queue_size=100000
- thread_pool.search.queue_size=100000
- thread_pool.bulk.queue_size=100000
ulimits:
nofile:
soft: 65536
hard: 65536
cortex:
image: thehiveproject/cortex:latest
ports:
- "0.0.0.0:9001:9001"
thehive:
image: thehiveproject/thehive:latest
depends_on:
- elasticsearch
- cortex
ports:
- "0.0.0.0:9000:9000"
// TODO
概念补充
消息队列
消息队列(Message Queue, MQ) = Message in Queue
简单来说,就是数据生产者和数据消费者之间的一个仓库,以前是生产者一产出数据,就亲手交给消费者,现在是生产者产出数据后,先放到消息队列这个仓库里,然后消费者按照自己的消费速度去拿。
好处有四个方面:
- 解耦合
- 降低代码耦合性,每个成员可以更独立,生产者不再需要亲手交到消费者手里,消费者想快点取也可以,慢点取也可以
- 提速
- 生产者只要完成生产后把货物放到仓库就可以了,不用再考虑与消费者的对接等其他操作
- 广播
- 生产者放到仓库后,所有人都可以来拿货物
- 削峰
- 消费者不用再根据生产者的速度来调整消费速度
References
[1] 浅谈基于开源工具的威胁情报自动化生产,果胜,https://paper.seebug.org/1210/
[2] 内生安全与威胁情报体系构建,吴云坤,https://github.com/FeeiCN/Security-PPT/blob/master/2020%20%E5%A5%87%E6%99%BA%E5%A8%81%E8%83%81%E6%83%85%E6%8A%A5%E5%B3%B0%E4%BC%9A/%E5%90%B4%E4%BA%91%E5%9D%A4-%E5%86%85%E7%94%9F%E5%AE%89%E5%85%A8%E4%B8%8E%E5%A8%81%E8%83%81%E6%83%85%E6%8A%A5%E4%BD%93%E7%B3%BB%E6%9E%84%E5%BB%BA.pdf